
🤵🏻 About me
I am a 1th year PhD student at Fudan University and Shanghai Innovation Institute, advised by Prof. Xiangyang Xue, Prof. Yanwei Fu, and Prof. Binxing Fang. My research focuses on Embodied AI, Spatial Intelligence, and Vision-Language-Action Models.
I am passionate about developing AI systems that integrate perception, reasoning, and action in complex environments. My work primarily involves 3D multi-modal reconstruction and how it can enable robotic manipulation. Feel free to connect with me via email: lzyzjhz@163.com.
🔥 News
- 2025.07: 🎉🎉 Our works on 3D Spatial Reasoning and Grounding have been accepted by ACMMM 2025. Big thank you to my co-authors!
- 2025.06: 🎉🎉 Our works on Visual Policy Learning have been accepted by ICCV 2025. Big thank you to my co-authors!
- 2025.04: Attending China3DV at Beijing, China.
- 2025.02: 🎉🎉 Our works on 3D Visual Grounding and Reasoning have been accepted by CVPR 2025. Big thank you to my co-authors!
📝 Publications
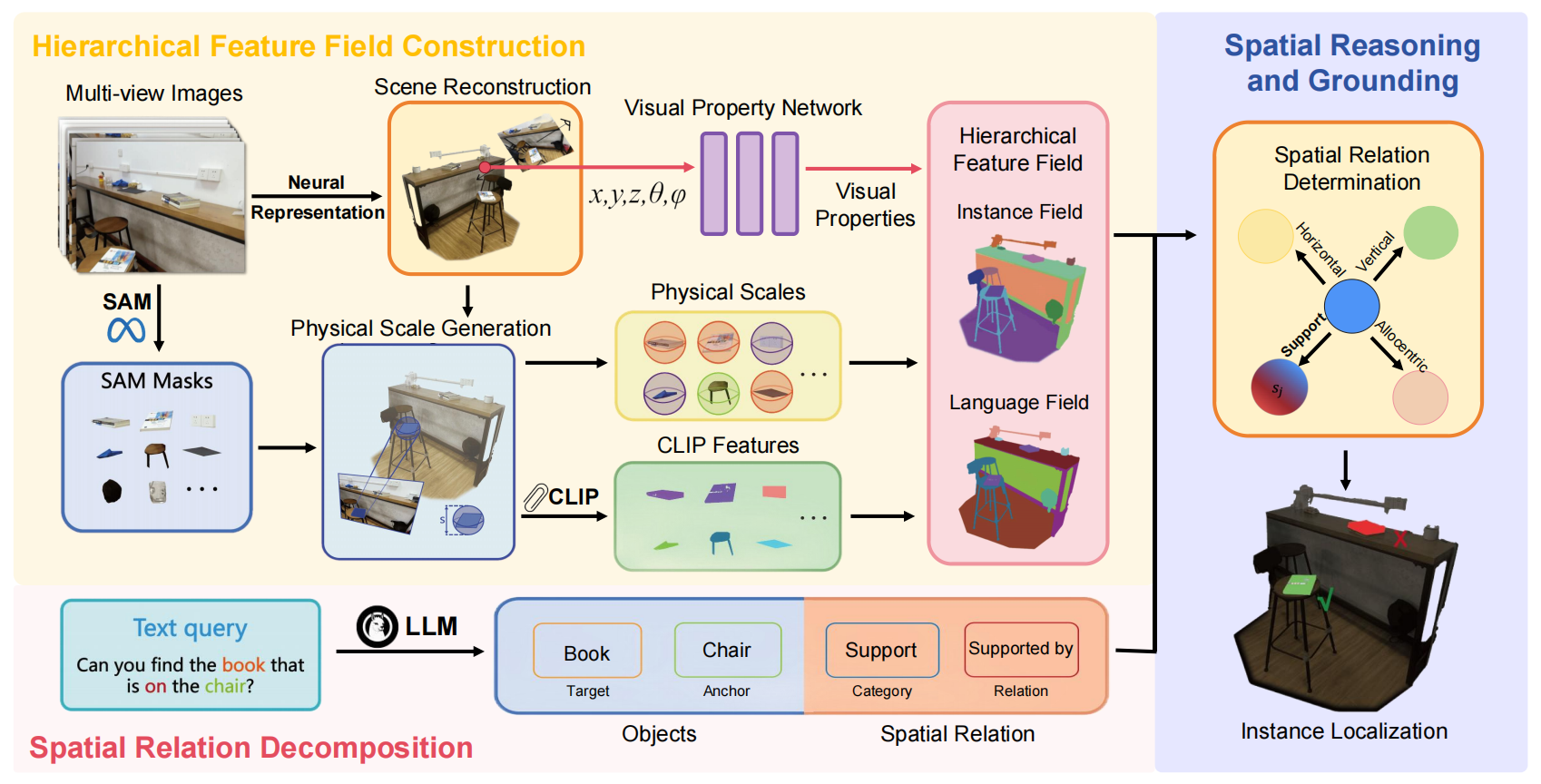
Zhenyang Liu, Sixiao Zheng, Siyu Chen, Cairong Zhao, Longfei Liang, Xiangyang Xue, Yanwei Fu, ACMMM 2025
In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding.
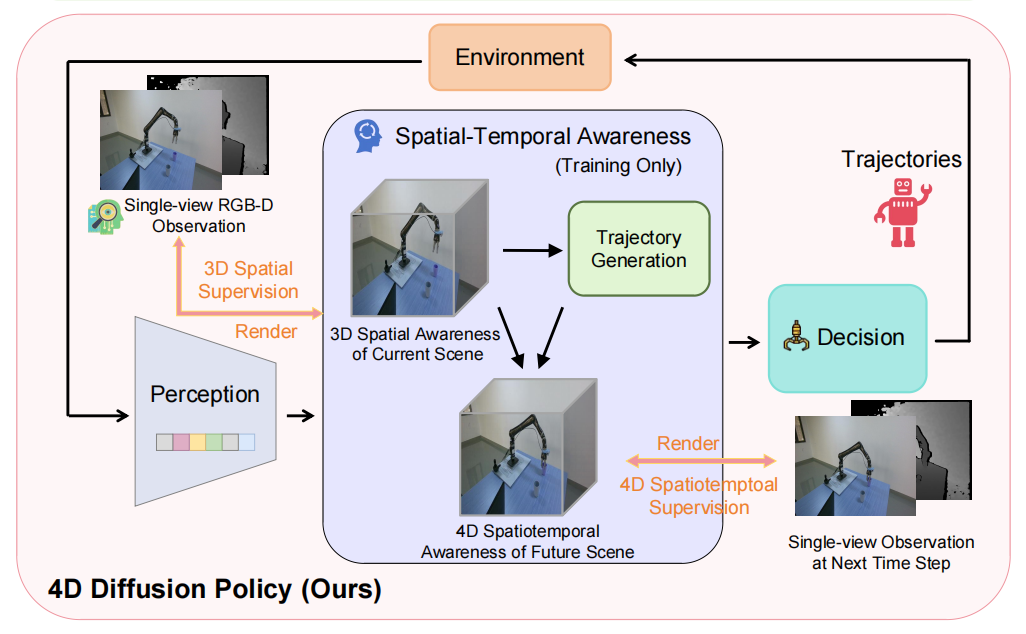
Spatial-Temporal Aware Visuomotor Diffusion Policy Learning
Zhenyang Liu, Yikai Wang, Kuanning Wang, Longfei Liang, Xiangyang Xue, Yanwei Fu, ICCV 2025
In this work, we propose 4D Diffusion Policy (DP4), a novel visual imitation learning method that incorporates spatiotemporal awareness into diffusion-based policies. Unlike traditional approaches that rely on trajectory cloning, DP4 leverages a dynamic Gaussian world model to guide the learning of 3D spatial and 4D spatiotemporal perceptions from interactive environments.
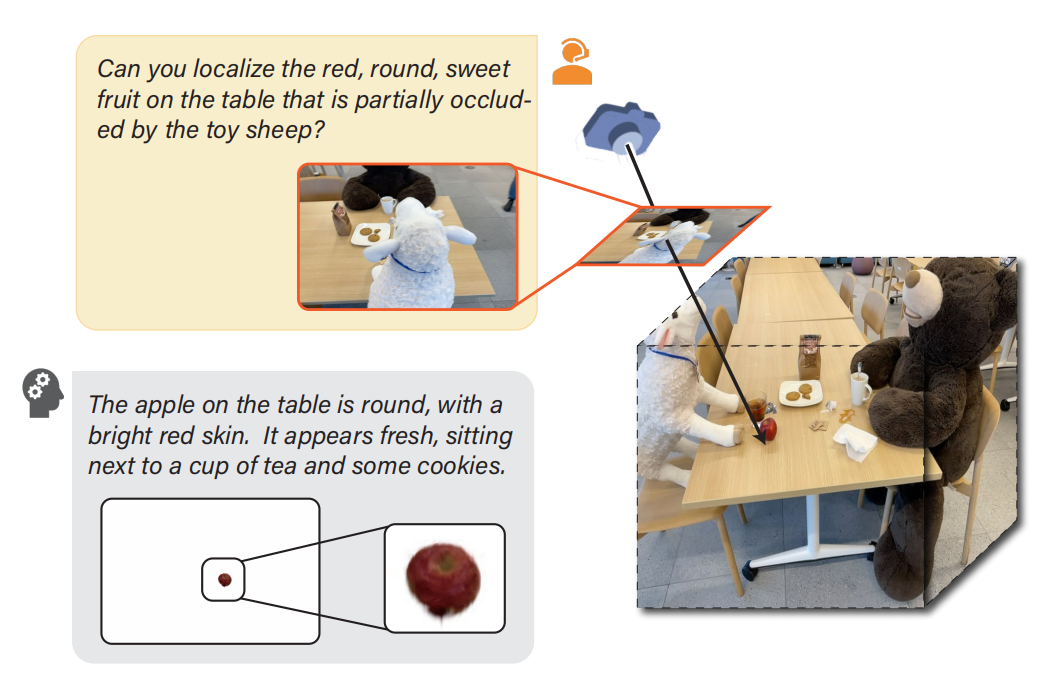
Zhenyang Liu, Yikai Wang, Sixiao Zheng, Tongying Pan, Longfei Liang, Yanwei Fu, Xiangyang Xue, CVPR 2025
ReasonGrounder is a novel LVLM-guided framework that uses hierarchical 3D feature Gaussian fields for adaptive grouping based on physical scale, enabling open-vocabulary 3D grounding and reasoning.
💻 Internships
- 2025.09 - Now, Tencent Hunyuan, Shanghai, China
- 2025.03 - 2025.09, Shanghai AI Laboratory, Shanghai, China
- 2021.04 - 2024.06, Media Intelligence Laboratory, Hangzhou, China